统计学习(7)--最大熵模型
摘要
支持向量机的学习的目标也是在特征空间中找到一个分离超平面,能将实例分到不同的类。不同与感知机的解有无穷多个,线性可分支持向量机利用间隔最大化求最优分离超平面,解是唯一的。
1.间隔
一般来说,一个点距离分离超平面的远近可以表示分类预测的确信程度。在超平面确定的情况下,点\(x_i\)与超平面的距离可以表示为函数
\[ \left|\frac{1}{\|w\|_{2}} \cdot\left(w \cdot x_i+b\right)\right| \]
定义函数间隔(functional margin)为下式
\[ \hat{\gamma}_{i}=y_{i}\left(w \cdot x_{i}+b\right) \]
记函数间隔\(\hat{\gamma}_{i}\)的最小值为\(\hat{\gamma}\),函数间隔可以表示分类预测的正确性及准确度。对超平面的法向量添加约束,就可以得到几何间隔(geometric margin),定义如下
\[ \gamma_{i}=y_{i}\left(\frac{w}{\|w\|} \cdot x_{i}+\frac{b}{\|w\|}\right) \]
1.1 最大间隔分离
最大间隔具有存在性和唯一性,训练数据集的样本点中与分离超平面距离最近的样本点的实例称为支持向量(support vector),在决定分离超平面时只有支持向量起作用,而其他实例点并不起作用。如果移动支持向量将改变所求的解;但是如果在间隔边界以外移动其他实例点,甚至去掉这些点,则解是不会改变的。
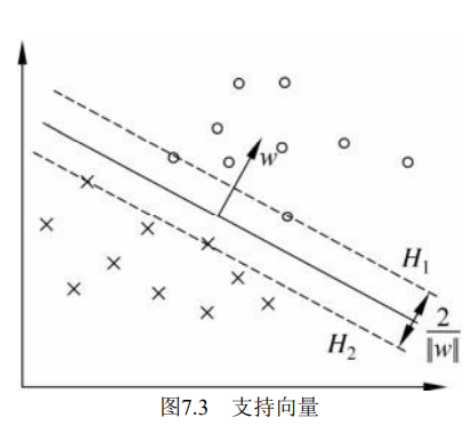
1.2 硬间隔
硬间隔(hard margin):假定训练样本在样本空间或特征空间中是线性可分的,即存在一个超平面能将不同类的样本完全划分开。
对于硬间隔分类,可以将问题转化为优化问题,即求
\[ \max _{w, b} \quad \hat{\gamma}_{i} \]
\[ \text { s.t. } y_{i}\left(\frac{w}{\|w\|} \cdot x_{i}+\frac{b}{\|w\|}\right) \geqslant \hat{\gamma}, \quad i=1,2, \cdots, N \]
使用几何间隔来替代间隔函数,这样对超平面的参数\(w,b\)的缩放就不影响结果,可以令几何最小间隔\(\hat{\gamma}=1\),将所求表达式转换为如下形式
\[ \max _{w, b} \frac{1}{\|w\|} \]
\[ \text { s.t. } \quad y_{i}\left(w \cdot x_{i}+b\right) \geqslant 1, \quad i=1,2, \cdots, N \]
可以进一步可以变为求最小值优化
\[ \min _{w, b} \frac{1}{2}\|w\|^{2} \]
\[ \text { s.t. } \quad y_{i}\left(w \cdot x_{i}+b\right)-1 \geqslant 0, \quad i=1,2, \cdots, N \]
1.3 软间隔
实际中训练数据的不等式约束并不能都成立。并不能满足硬间隔,这就需 要修改硬间隔最大化,使其成为软间隔最大化。
为了解决这个问题,可以对每个样本点\((x_i,y_i)\)引进一个松弛变量\(\xi_{\mathrm{i}} \geq 0\),使函数间隔加上松弛变量大于等于1。这样,约束条件变为
\[ y_{i}\left(w \cdot x_{i}+b\right) \geqslant 1-\xi_{i} \]
2.对偶算法
2.1 对偶关系证明
使用拉格朗日乘子法引入对偶算法,注意这里要用小于0的约束条件
\[ L(w, b, \lambda)=\frac{1}{2}\|w\|^{2}+\sum_{i=1}^{N} \lambda_{i} (1-y_{i}\left(w \cdot x_{i}+b\right)) \]
其中\(\lambda\)是拉格朗日乘子,要求大于等于0
原问题就转化为
\[ \max _{\lambda} \min _{w, b} L(w, b, \lambda) \]
\[ \text { s.t. } \lambda_{i} \geqslant 0 \]
这里解释一下取极大极小值的意义,。先将\(\frac{1}{2}\|w\|^{2}\)记为\(f(w)\),后一项记为\(\lambda g(w,b)\) \[ \begin{align} \max _{\lambda}\min _{w, b} L(w, b, \lambda) &= \max_{\lambda}\min_{w, b} f(w)+ \max_{\lambda}\min_{w, b} \lambda g(w,b)\nonumber \\ &= \min_{w} f(w) + \max_{\lambda}\min_{w, b} \lambda g(w,b) \nonumber \end{align} \]
因为\(y_{i}\left(w \cdot x_{i}+b\right)\geqslant 1\),所以\(g(w,b)\)小于等于0,上式后一项的最大值就是0,即
\[ \max _{\lambda}\min _{w, b} L(w, b, \lambda) = \min_{w}\frac{1}{2}\|w\|^{2} \]
和原式等价。
有些视频和书上最大最小符号前后是换位的,在该问题下是等价的,因为有\(g(w,b)\)小于等于0,所以
\[ \max_{\lambda} L(w,b,\lambda) = f(w) \]
所以有
\[ \min_{w,b} f(w) = \min_{w,b} \max_{\lambda} L(w,b,\lambda) = \max _{\lambda}\min _{w, b} L(w, b, \lambda) \]
2.2 拉格朗日求解
将拉格朗日函数分别对\(w,b\)求导
\[ \nabla_{w} L(w, b, \lambda)=w-\sum_{i=1}^{N} \lambda_{i} y_{i} x_{i}=0 \]
\[ \nabla_{b} L(w, b, \lambda)=\sum_{i=1}^{N} \lambda_{i} y_{i}=0 \]
所以有
\[ w=\sum_{i=1}^{N} \lambda_{i} y_{i} x_{i} \]
\[ \sum_{i=1}^{N} \lambda_{i} y_{i}=0 \]
将上式回代\(L(w, b, \lambda)\)得
\[ \begin{aligned} L(w, b, \lambda) & =\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \lambda_{i} \lambda_{j} y_{i} y_{j}\left(x_{i} \cdot x_{j}\right)\\ &-\sum_{i=1}^{N} \lambda_{i} y_{i}\left(\left(\sum_{j=1}^{N} \lambda_{j} y_{j} x_{j}\right) \cdot x_{i}+b\right)+\sum_{i=1}^{N} \lambda_{i} \\ & =-\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \lambda_{i} \lambda_{j} y_{i} y_{j}\left(x_{i} \cdot x_{j}\right)+\sum_{i=1}^{N} \lambda_{i} \end{aligned} \]
这就是\(\min _{w, b} L(w, b, \lambda)\),接下来对它求极大值
即求负的极小值
\[ \min _{\lambda} \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \lambda_{i} \lambda_{j} y_{i} y_{j}\left(x_{i} \cdot x_{j}\right)+\sum_{i=1}^{N} \lambda_{i} \]
\[ \begin{array}{ll} \text { s.t. } & \sum_{i=1}^{N} \lambda_{i} y_{i}=0 \\ & \lambda_{i} \geqslant 0, \quad i=1,2, \cdots, N \end{array} \]
参考资料
[1] 《统计学习方法》 李航